[PYTHON] [MATHS] Méthode du gradient à pas fixe

Bonjour, je dois coder une méthode du gradient à pas fixe pour un cours de maths-info. C'est un problème de minimisation et je dois trouver le minimum d'une fonction à partir de plusieurs algorithmes dont celui du gradient à pas fixe. Néanmoins je suis confronté à une erreur de divergence de mon algorithme. Je suis censé converger vers x1,x2=[1,1] et f(x1,x2)=2. Ce que je ne trouve pas. Quelles sont les erreurs que j'ai pu commettre. Merci d'avance.
ce que j'obtiens (pour 4 itérations, mais pour encore plus ça diverge bien plus)
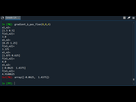
le programme:
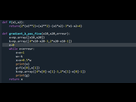
Note que ton code n'utilise pas f pour calculer le gradient... Mais utilise les derives partielles calculer manuellement.
Note que tu peux vouloir harmonizer les notations dans ton code parceque les x1 deviennent des x[0]. Ce qui est correct en terme de logique, mais super difficile a lire.
Ne pas utiliser f dans le calcul du grad n'a pas une grande incidence, non ?
Aussi je tiens à préciser que j'ai la bonne première itération
non ca n'a pas grande incidence tant que le calcul du gradient est correcte. Et il m'a l'air correcte ici.
Je pense que le deuxieme pas est egalement correcte. En regardant les valeures, la gueule de la fonction, et de la derive, j'ai l'impression que ce qu'il se passe est que ca methode oscille autour du minimum en s'eloignant du minimum a chaque etape.
Ca m'a l'air d'indique que le pas est trop grand. Si tu ajuste de 1% de l'oppose du gradient, ca se passe mieux?
ouais, c'est ca:
import numpy as np
def f(x1, x2):
return 2*(x1**2)+x2**2 - x1*x2 - 3*x1-x2+4
def grad(x10, x20, err):
x=np.array([x10,x20])
for e in range(0,err):
k=np.array([4*x[0]-x[1]-3, 2*x[1]-x[0]-1])
w=-k
direction=0.5*w
print ("direction: "+str(direction))
print ("norm: "+str(np.linalg.norm(direction)))
x = x+direction
print("newx: "+str(x))
g=f(x[0],x[1])
print ("f(newx): " +str(g))
return x
print (grad(0,0,10))
Faire tourner ca donne:
$ python3 grad.py
direction: [1.5 0.5]
norm: 1.5811388300841898
newx: [1.5 0.5]
f(newx): 3.0
direction: [-1.25 0.75]
norm: 1.4577379737113252
newx: [0.25 1.25]
f(newx): 3.375
direction: [ 1.625 -0.625]
norm: 1.741048534648015
newx: [1.875 0.625]
f(newx): 4.0
direction: [-1.9375 0.8125]
norm: 2.1009670392464512
newx: [-0.0625 1.4375]
f(newx): 4.9140625
direction: [ 2.34375 -0.96875]
norm: 2.5360679456591853
newx: [2.28125 0.46875]
f(newx): 6.24609375
direction: [-2.828125 1.171875]
norm: 3.0613039756368527
newx: [-0.546875 1.640625]
f(newx): 8.18701171875
direction: [ 3.4140625 -1.4140625]
norm: 3.6953207584474312
newx: [2.8671875 0.2265625]
f(newx): 11.01513671875
direction: [-4.12109375 1.70703125]
norm: 4.460646745121791
newx: [-1.25390625 1.93359375]
f(newx): 15.136016845703125
direction: [ 4.97460938 -2.06054688]
norm: 5.384476934476566
newx: [ 3.72070312 -0.12695312]
f(newx): 21.140579223632812
direction: [-6.00488281 2.48730469]
norm: 6.499638620747878
newx: [-2.28417969 2.36035156]
f(newx): 29.889867782592773
[-2.28417969 2.36035156]
Tu peux voir que la norme du vecteur de direction augmente. Si tu change le multiplicateur par 0.1, ca se passe beaucoup mieux:
$ python3 grad.py
direction: [0.3 0.1]
norm: 0.316227766016838
newx: [0.3 0.1]
f(newx): 3.16
direction: [0.19 0.11]
norm: 0.2195449840010015
newx: [0.49 0.21]
f(newx): 2.7414
direction: [0.125 0.107]
norm: 0.1645417880053575
newx: [0.615 0.317]
f(newx): 2.499984
direction: [0.0857 0.0981]
norm: 0.13026165974683418
newx: [0.7007 0.4151]
f(newx): 2.34620842
direction: [0.06123 0.08705]
norm: 0.10642751242042635
newx: [0.76193 0.50215]
f(newx): 2.2426861228
direction: [0.045443 0.075763]
norm: 0.08834646805617076
newx: [0.807373 0.577913]
f(newx): 2.171062405278
direction: [0.0348421 0.0651547]
norm: 0.07388576902557081
newx: [0.8422151 0.6430677]
f(newx): 2.1208742888570398
direction: [0.02742073 0.05560797]
norm: 0.062001151289744615
newx: [0.86963583 0.69867567]
f(newx): 2.085504089308271
direction: [0.02201324 0.04722845]
norm: 0.05210670695899739
newx: [0.89164906 0.74590412]
f(newx): 2.0605130406859162
direction: [0.01793079 0.03998408]
norm: 0.043820542583953466
newx: [0.90957985 0.7858882 ]
f(newx): 2.042835448171438
[0.90957985 0.7858882 ]
Si tu met 0.3, ca converge beaucoup plus vite:
$ python3 grad.py
direction: [0.9 0.3]
norm: 0.9486832980505137
newx: [0.9 0.3]
f(newx): 2.44
direction: [-0.09 0.39]
norm: 0.40024992192378994
newx: [0.81 0.69]
f(newx): 2.1094
direction: [0.135 0.129]
norm: 0.18672439583514525
newx: [0.945 0.819]
f(newx): 2.028856
direction: [0.0117 0.0921]
norm: 0.09284018526478716
newx: [0.9567 0.9111]
f(newx): 2.00780362
direction: [0.02529 0.04035]
norm: 0.04762044308907673
newx: [0.98199 0.95145]
f(newx): 2.0021314372
direction: [0.007047 0.023727]
norm: 0.024751378507065002
newx: [0.989037 0.975177]
f(newx): 2.000584421518
direction: [0.0057087 0.0116049]
norm: 0.012933018197621188
newx: [0.9947457 0.9867819]
f(newx): 2.0001604816417604
direction: [0.00233973 0.00635457]
norm: 0.006771624351497958
newx: [0.99708543 0.99313647]
f(newx): 2.000044093241999
direction: [0.00143842 0.00324375]
norm: 0.003548374427908392
newx: [0.99852385 0.99638022]
f(newx): 2.0000121175125125
direction: [0.00068544 0.00172903]
norm: 0.0018599351348637144
newx: [0.99920929 0.99810924]
f(newx): 2.000003330360061
[0.99920929 0.99810924]
Oui, merci de m'avoir éclairé sur ce problème de pas, bref, c'est l'énoncé qui était mal foutu, il mentionnait d'utiliser 0.5 mais rien ne laissait supposer que ça ne convergeait pas. Merci beaucoup.
L'enonce etait mal foutu, ou bien l'enonce a ete constuit pour te faire poser la question "pourquoi ca converge pas"
- Aide à l'achat Mac
- Macintosh
- Création de sites web
- Création de Jeux
- Linux
- Programmation
- Internet
- Steam Deck
- Hardware